
This project skeleton was created to standardize and streamline data analysis workflows in organizational settings. It provides a structured, modular approach to data analysis tasks, enhancing productivity, maintainability, and collaboration among data analysts.
Importance of This Approach
- Modularity: Each component (pre-processing, analysis, visualization) is separate, making it easier to maintain and update individual parts without affecting others.
- Reusability: Functions and modules can be easily reused across different projects or shared with team members.
- Consistency: A standardized structure ensures all data analysis projects within the organization follow the same pattern, improving readability and understanding.
- Collaboration: Clear organization allows multiple analysts to work on different parts of the project simultaneously without conflicts.
- Reproducibility: Well-structured code, along with environment specifications, ensures that analyses can be easily reproduced by others.
- Scalability: As projects grow, the modular structure makes it easier to add new features or expand existing functionality.
- Version Control: The structure is designed to work well with version control systems, making it easier to track changes and collaborate.
- Productivity: By providing a ready-to-use structure, analysts can focus on actual data analysis rather than project setup and organization.
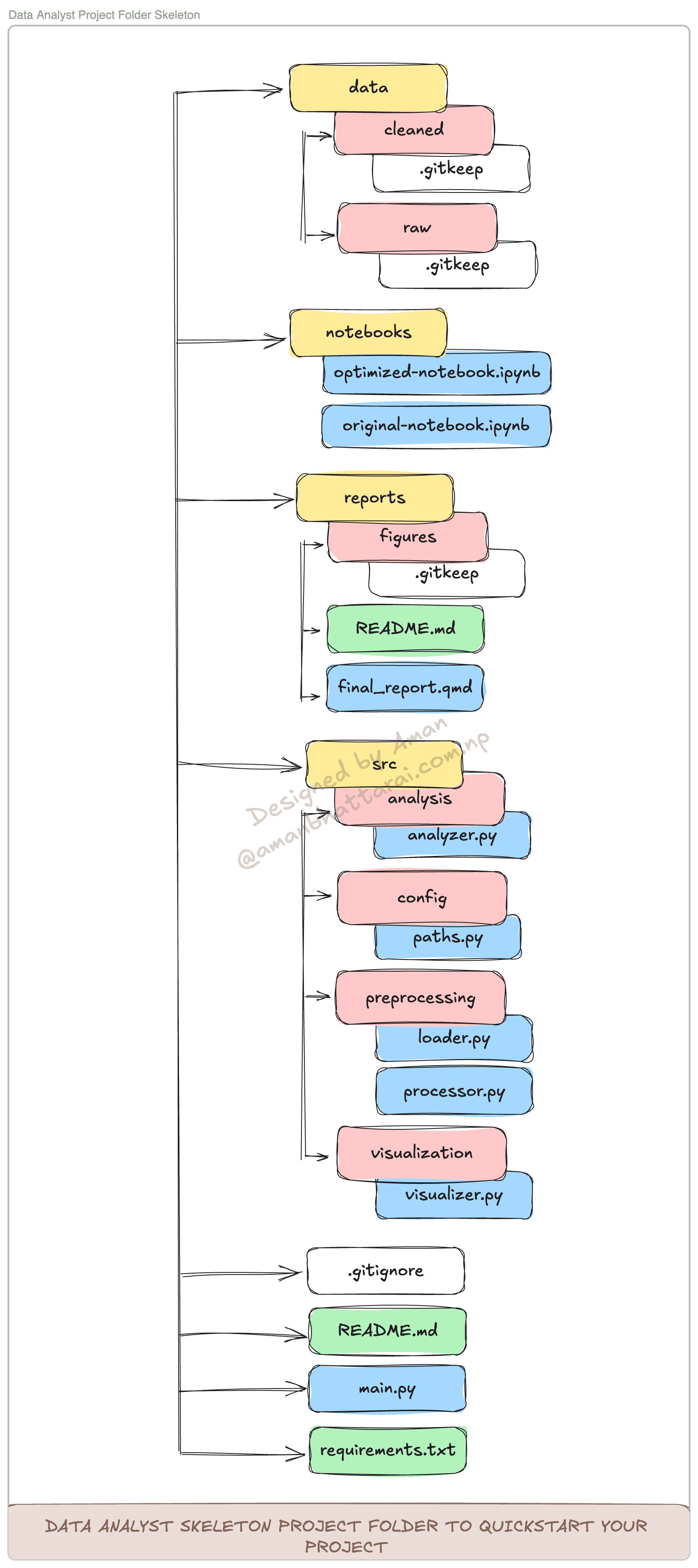
Project Structure
data/:raw/: Original, immutable datacleaned/: Processed, analysis-ready data
src/:config/: Configuration files (e.g., paths)preprocessing/: Data loading and processing scriptsanalysis/: Data analysis functionsvisualization/: Data visualization scripts
notebooks/: Jupyter notebooks for exploratory analysisreports/: Output directory for figures and final reports.gitignore: Ignore the files and folders when uploading to Githubmain.py: Entry point for running the entire pipelinerequirements.txt: Project dependenciesREADME.md: Project documentation
How It Works
- The project uses modular programming to separate the process of:
- Data loading and pre-processing
- Analysis
- Visualization
main.pyruns the entire data analysis pipeline- Individual modules can be imported into Jupyter notebooks for interactive analysis, or you can utilize
original-notebook.ipynbfor ease to work on notebook environment.
Required Steps
- Clone this repository and remove
.gitkeep. - Place your raw data in
data/raw/ - Make necessary changes in python files.
- Run the analysis:
python main.py - Utilize Quarto to generate final reports.
Note: If you are initially uncomfortable with running python files, code your program in notebooks/original-notebook.ipynb and convert each step into functions and append them in processor.py or analyzer.py or visualizer.py accordingly.
Generating requirements.txt
You can use pipreqs to automatically generate the requirements.txt file.
pip install pipreqsRun pipreqs --force in your project folder directory, if not pass the path as pipreqs --force path/to/project/directory.
Image by freepik
Thank you 😊 👨💻